故障现象
收到告警,有主机处于NotReady状态,并且该主机的cpu使用率,内存使用率,负载都很高。
故障排查
登陆容器,查看node状态,发现主机处于NotReady状态。
 查看主机内的容器状态,发现部分pod处于“删除中”状态,部分pod处于“重启”状态。
查看主机内的容器状态,发现部分pod处于“删除中”状态,部分pod处于“重启”状态。
 登陆华为云,查看主机监控,发现cpu使用率,内存使用率,负载都很高。
登陆华为云,查看主机监控,发现cpu使用率,内存使用率,负载都很高。
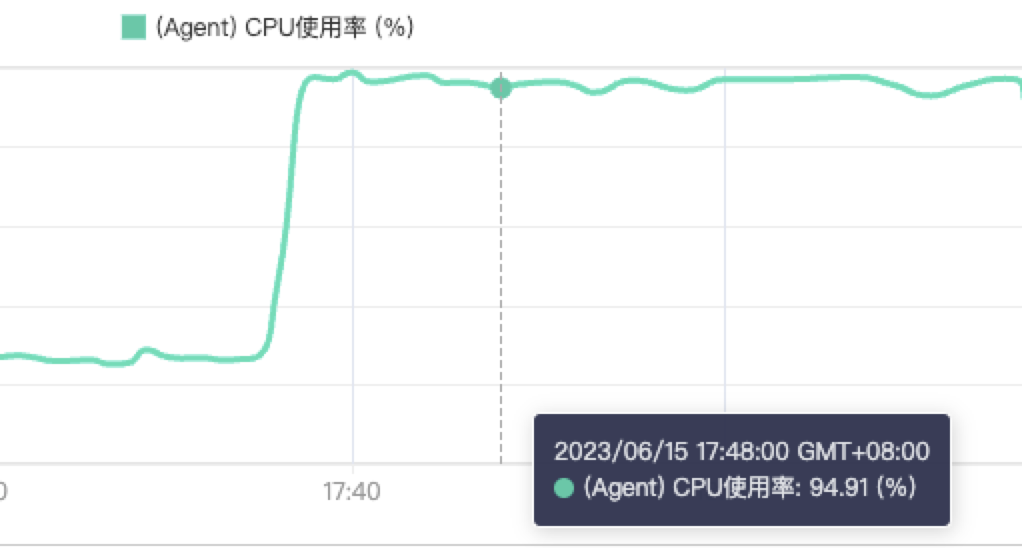
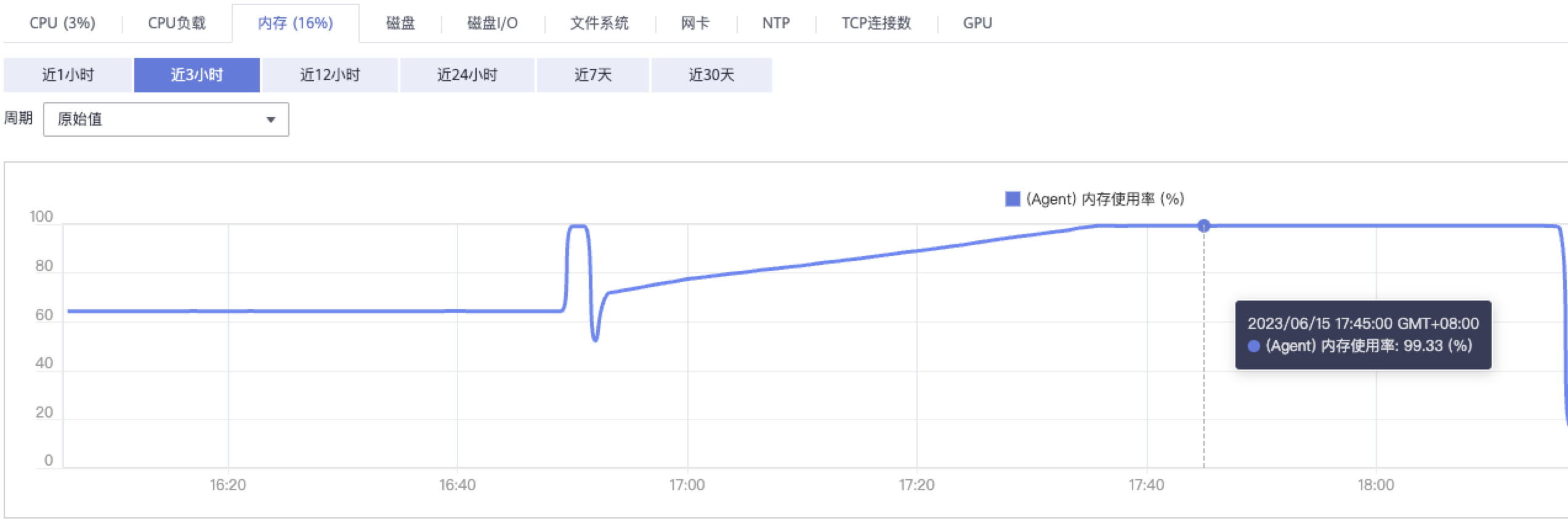
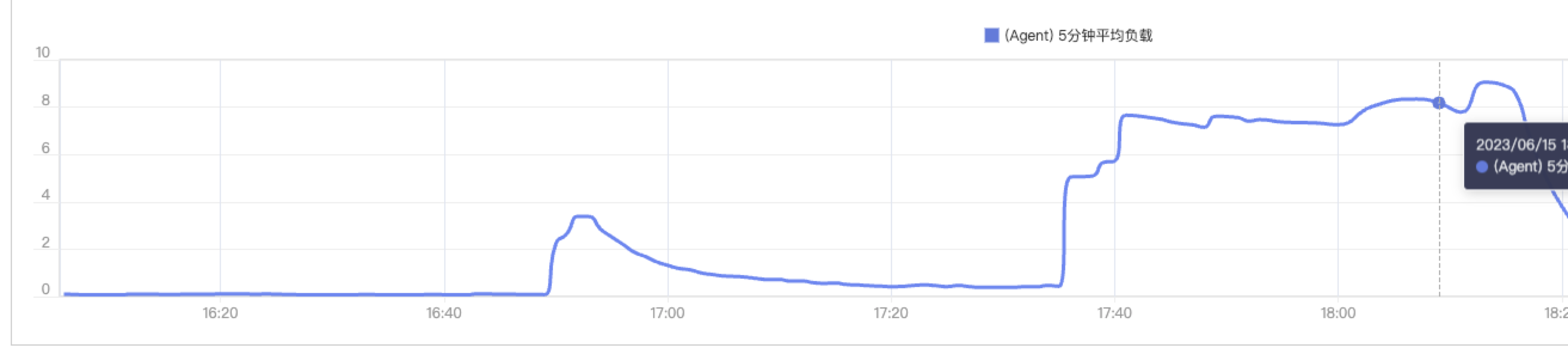
经过监控验证,排除告警误告的情况;
因为主机负载较高,无法通过ssh连接node,所以通过手动的方式,将主机内业务容器迁移调度到其他主机内;
之后对node进行重启,经过重启后查看主机cpu,内存,负载已经恢复稳定,并且状态也已经恢复Ready状态。
通过ssh登陆主机,查看相关日志,排查故障产生的原因。
在日志内,发现主机在不停的kill部分pod进程,并且kill的pid是持续改变的;
由于主机一直处于NotReady状态,这说明主机OOM之后主机在删除相关pod,但是因为daemonset的原因pod再重启,在pod启动后又一次占据了内存导致内存OOM;
因此一直处于重启,然后处于oom-killer的死循环状态。
Jun 15 16:50:50 online-1-19-10-30740-b7pqf kernel: Out of memory: Kill process 3241 (filebeat) score 1004 or sacrifice child
Jun 15 16:50:50 online-1-19-10-30740-b7pqf kernel: Killed process 3241 (filebeat), UID 0, total-vm:1702220kB, anon-rss:75196kB, file-rss:0kB, shmem-rss:0kB
Jun 15 16:52:31 online-1-19-10-30740-b7pqf kernel: Out of memory: Kill process 18271 (java) score 1002 or sacrifice child
Jun 15 16:52:31 online-1-19-10-30740-b7pqf kernel: Killed process 18271 (java), UID 1000, total-vm:10065552kB, anon-rss:5265332kB, file-rss:0kB, shmem-rss:0kB
Jun 15 16:52:31 online-1-19-10-30740-b7pqf kernel: Out of memory: Kill process 18518 (java) score 1002 or sacrifice child
Jun 15 16:52:31 online-1-19-10-30740-b7pqf kernel: Killed process 21215 ([main]-pipeline), UID 1000, total-vm:10065552kB, anon-rss:5265472kB, file-rss:0kB, shmem-rss:0kB
Jun 15 17:36:56 online-1-19-10-30740-b7pqf kernel: Out of memory: Kill process 8437 (filebeat) score 1006 or sacrifice child
Jun 15 17:36:56 online-1-19-10-30740-b7pqf kernel: Killed process 8437 (filebeat), UID 0, total-vm:1079696kB, anon-rss:103664kB, file-rss:0kB, shmem-rss:0kB
Jun 15 17:38:41 online-1-19-10-30740-b7pqf kernel: Out of memory: Kill process 9614 (icagent) score 1001 or sacrifice child
Jun 15 17:38:41 online-1-19-10-30740-b7pqf kernel: Killed process 9614 (icagent), UID 0, total-vm:1438452kB, anon-rss:20912kB, file-rss:0kB, shmem-rss:0kB
Jun 15 18:07:17 online-1-19-10-30740-b7pqf kernel: Out of memory: Kill process 9119 (sh) score 999 or sacrifice child
Jun 15 18:07:17 online-1-19-10-30740-b7pqf kernel: Killed process 15816 (sleep), UID 0, total-vm:4380kB, anon-rss:76kB, file-rss:0kB, shmem-rss:0kB
Jun 15 18:15:08 online-1-19-10-30740-b7pqf kernel: Out of memory: Kill process 9119 (sh) score 999 or sacrifice child
Jun 15 18:15:08 online-1-19-10-30740-b7pqf kernel: Killed process 9119 (sh), UID 0, total-vm:11900kB, anon-rss:420kB, file-rss:24kB, shmem-rss:0kB
Jun 15 18:15:09 online-1-19-10-30740-b7pqf kernel: Out of memory: Kill process 8877 (edaemon) score 999 or sacrifice child
Jun 15 18:15:09 online-1-19-10-30740-b7pqf kernel: Killed process 8877 (edaemon), UID 0, total-vm:1328412kB, anon-rss:11712kB, file-rss:0kB, shmem-rss:0kB
查看主机相关内存设置,发现业务limit是处于超出限制状态的。
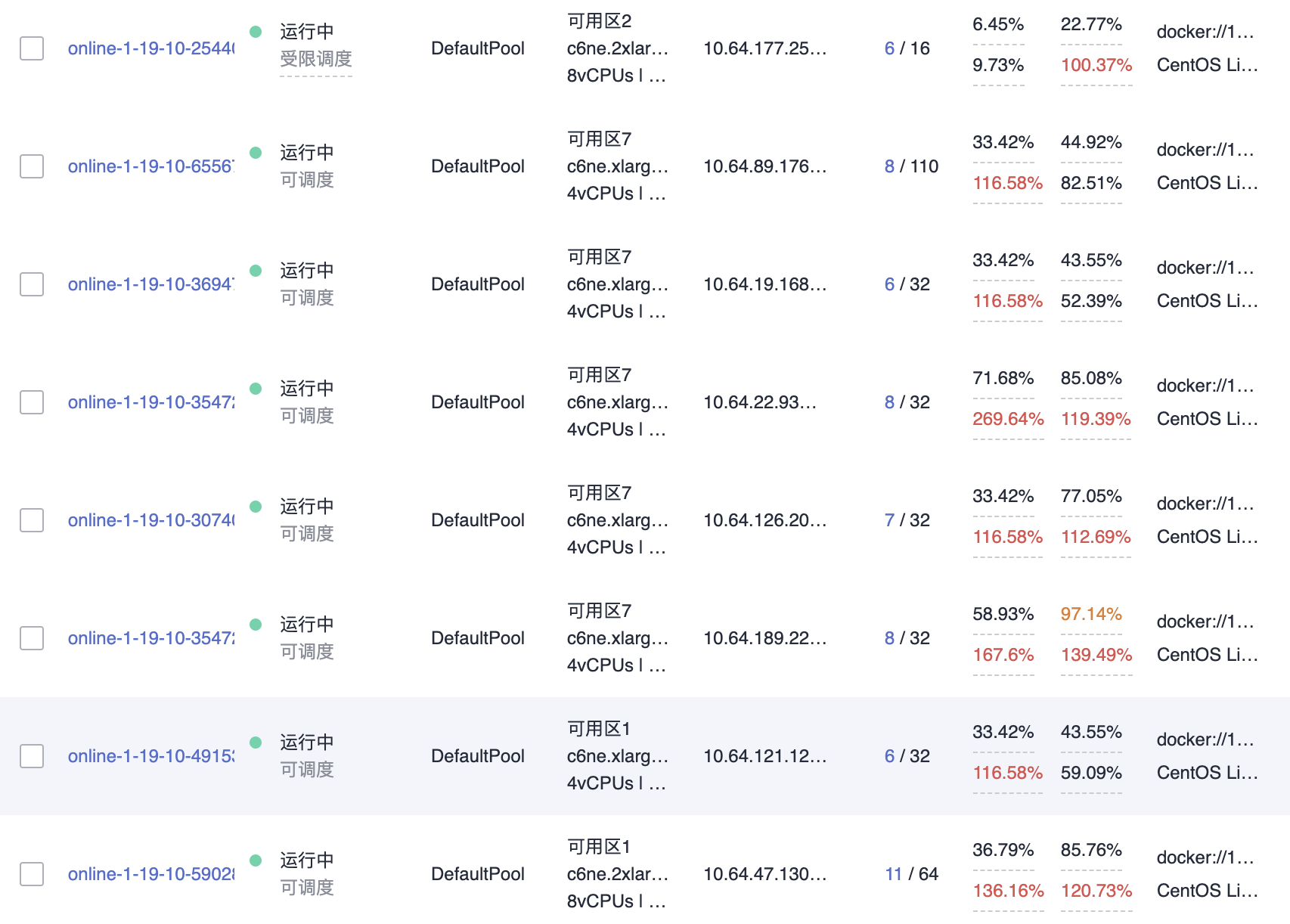 查看主机的kubelet设置,发现主机设置的内存预留为100M,
查看主机的kubelet设置,发现主机设置的内存预留为100M,
root 16952 16658 3 18:16 ? 00:03:43 /usr/local/bin/kubelet --bootstrap-kubeconfig=/opt/cloud/cce/kubernetes/kubelet/boot.conf --cert-dir=/opt/cloud/cce/kubernetes/kubelet/pki --rotate-certificates=true --network-plugin=cni --cni-conf-dir=/etc/cni/net.d/ --node-ip=10.64.70.45 --provider-id=f91cee63-4380-11ec-870d-0255ac101de7 --kubeconfig=/opt/cloud/cce/kubernetes/kubelet/kubeconfig --config=/opt/cloud/cce/kubernetes/kubelet/kubelet_config.yaml --authentication-token-webhook=true --pod-infra-container-image=cce-pause:3.1 --root-dir=/mnt/paas/kubernetes/kubelet --hostname-override=10.64.70.45 --v=2 --node-labels=os.name=CentOS_Linux_7_Core,os.version=3.10.0-1160.25.1.el7.x86_64,os.architecture=amd64,failure-domain.beta.kubernetes.io/zone=cn-north-4g,failure-domain.beta.kubernetes.io/region=cn-north-4,,node.kubernetes.io/subnetid=3466f66c-14d2-4b15-a61c-5739c6fdb420,node.kubernetes.io/baremetal=false,node.kubernetes.io/container-engine=docker --machine_id_file=/var/paas/conf/server.conf --cadvisor-port=4194 --cloud-provider=external --general-config-dir=/opt/cloud/cce/conf --kube-reserved=cpu=80m,memory=100Mi
故障原因
- 由于主机kubelet设置内存预留为100M,并且节点上面limit设置的值是远远超出主机本身的上限(虽然即使这样设置我的k8s的集群利用率依旧仅为78%),所以当该机器的一个Pod正在被终止(业务正在发版),系统就需要额外的内存去清理该pod,从而触发该机器的OOM(Out Of Memory)。
- 对于Linux系统来说oom kill程序并非是直接kill占用内存最大的程序,而是根据oomscore 机制 进行kill 程序,oomscore 得分越高的进程会被优先杀掉。系统kill了daemonset所产生的filebeat程序,但是内存释放后由于filebeat程序是daemonset所启动的所以又会自动创建,这就导致了内存又一次达到了OOM的临界点,从而导致主机一直处在创建与删除filebeat程序之间的状态。
- 主机不停处于oom-killer的过程中,负载很高,而kubelet的PLEG会由于负载问题导致 not healthy,当主机的PLEG超出3分钟not healthy后,k8s就会将node节点判定NodeNotReady的状态从而无法对外提供服务。
解决方案
- 主机NotReady状态是因为系统资源不足导致系统OOM,可以在通过迁移节点上业务pod后,重启节点降低资源占用来解决。
- 日志内PLEG is not healthy的报错信息是"容器运行时"与kubelet通信失败导致的,通过重启kubelet解决。
优化
- 增加kubelet的内存预留为1G,防止因为oom导致kubelet崩溃,主机出现notready状态。
- 设置daemonset 的内存request及limit设置,即使daemonset的内存占用较低,但是依旧需要设置,防止可能会出现的频繁oomkill的现象。
- 优化limit设置,防止主机日常运行时就出现处于内存崩溃边缘的状态(之前看主机内存正常情况下运行为97%)。
经验总结
- pod状态为“Terminating”时是优雅退出的,可能需要一些资源去清理。
当Kubernetes将Pod标记为Terminating时,其实是给容器发送信号告诉它们要退出。有些容器会很快响应这个信号,但有些容器可能会执行一些清理或保存状态等操作,这就需要在执行这些操作的过程中分配更多的内存,以防止出现严重的内存泄漏问题。 - 运行集群资源冗余同时也要允许节点的资源冗余。
如果主机内存已经非常紧张,容器可能无法分配额外的内存来完成退出操作,从而导致OutOfMemory(OOM)问题的发生,所以在对集群利用率优化的同时需要留意集群和节点的资源冗余。
作者介绍
- 廉帅 高级SRE工程师