
如上图,2亿华人都在使用的日历-中华万年历,给大家提供了实用、方便的服务。
那又是怎样的技术团队,在给我们中华万年历提供技术支撑服务了?
答案就是我们的后台技术中心团队,主要包括开发团队和SR团队。
在这里重点介绍下我们的SR团队的演进过程以及dev和ops的合作。
在互联网公司都有运维团队,我们的SR其实主要包括运维和安全。
SR=site reliability=system reliability + service reliability + speed reliability + security reliability
(系统可靠、服务可靠、响应速度可靠、安全可靠)
SR的基本职责是:
确保站点的可靠性、可用性、安全;
确保系统、服务能正常、平稳、不间断的运营;
确保响应速度,在出现故障时能及时响应和处理;
确保服务、代码的上线、变更是受控的、能够及时的持续交付;
确保系统架构中各层级的安全性,特别是数据安全;
确保容量规划的合理性,满足业务成长的需要,尽力提升网络质量,提升服务器等设备的可用性和利用率。
阶段一(2012) no ops

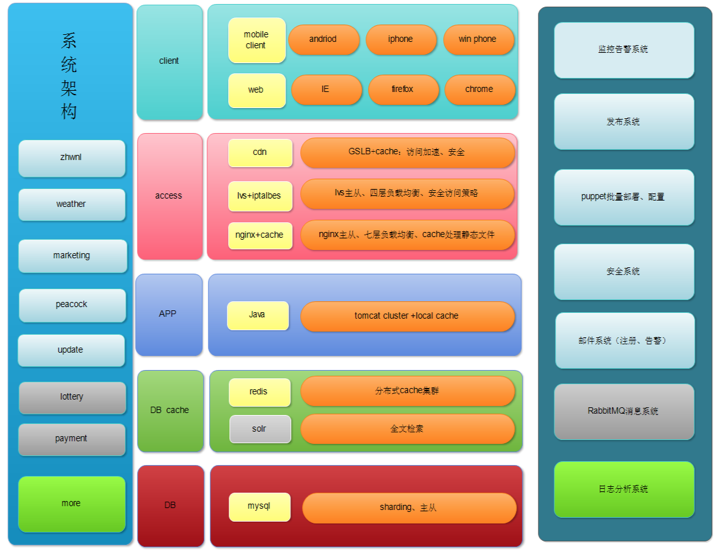
中华万年历里程碑版本(云同步版本)上线的时候,跟server端有关的主要的功能模块:数据云同步,天气,记事。
server端项目比较少,主要包括zhwnl、weather、marketing
devops(no ops、only dev)
idc托管、淘宝淘服务器组装
软路由vytta转发
手工wget war单台发布
nagios+cacti监控
阶段二(2012-2014) all in one
在中华万年历用户暴增的情况下,系统架构没有太多更新,但是需要维护的项目、服务器节点也相应增多;
当时只有一个运维,所有大多时间是花在基础平台的维护和优化,以及业务运维。
感谢两位当时短暂加入的小伙伴。
主要的工作如下:
基础运维:网络优化,idc、cdn建设,硬件选型购买,接入层优化
应用运维:nginx、tomcat、redis、mysql的配置和优化
平台运维:发布系统、批量配置
安全:入口iptables
邮件系统、虚拟化
阶段三(2014-2016)人肉运维
主要还是人肉运维 项目增多,系统架构越来越复杂,接入大数据各种组件、中间件服务、基础组件 新知识太多,疲于业务需求和学习,没有时间来升级运维平台; 同时我们也在认真考虑在人手不足的情况下,如何解脱自己,如何和开发更高效的协作。
阶段四(2016-now) SR
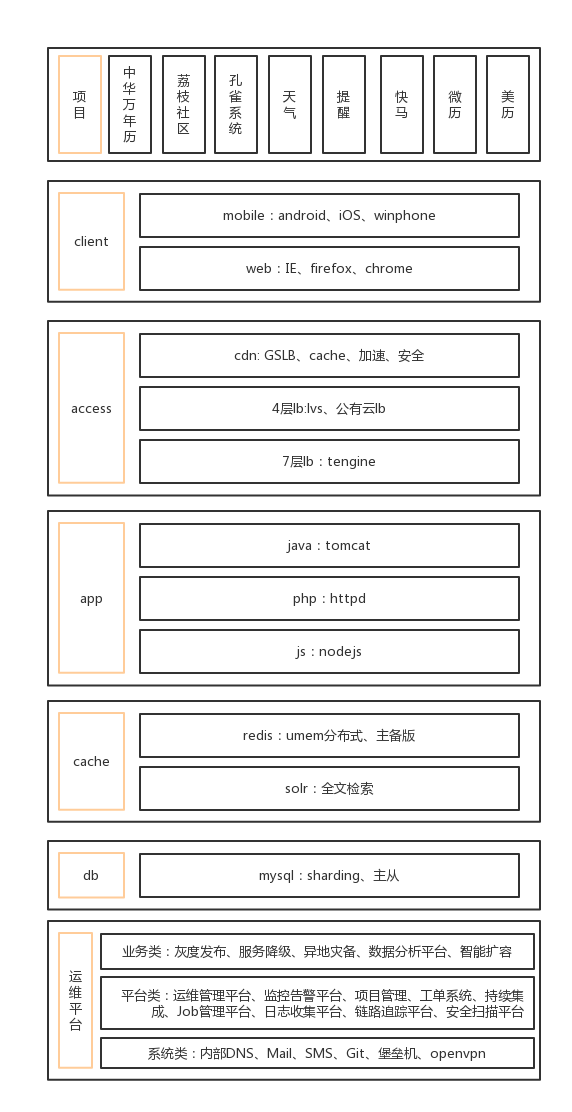
仅从如下两图可以看到,我们的项目越来越多,用的服务也越来越多,我们遇到的问题也越来越多,急需解决。
2016年初,我们找来了一位很给力的应届生小伙伴;
2017年初,我们又找来一位很给力的应届生小伙伴;
在我们的小伙伴熟悉我们的基础架构以及业务后,我们开始尝试做更多的事情。
先说下我们遇到的问题:
1. 传统idc运维,时间、人力成本高、idc本身限制的问题
2. 节日提醒ddos攻击问题
3. 故障预警、处理不及时、事故频发的问题
4. 团队建设的问题
5. devops的问题
传统idc运维,时间、人力成本高、idc本身限制的问题
节日提醒ddos攻击问题
以上两个问题有一定关联性,放在一起介绍下。
建设混合云数据中心
在最初公有云不是很火的时候,我们也是租用传统idc的机柜,自己买硬件设备,自己做虚拟化。
在这里我们遇到了一些问题:
最初选择的idc质量不佳,我们需要重新评估idc质量,选择更好的idc。
这时候你需要做一个工作,idc整体迁移到新的idc。
在2014年之前,我们花了接近半年时间,在保证我们线上所有服务不中断的情况下,把我们线上10多个项目,10多台物理服务器迁移到了最贵的idc,但是这种工作,会耗费大量的人力,时间。
但是紧接着,我们的产品和业务对我们提出了更高的要求,需要保证我们的app在我们节日提醒时候的可用率。
因为产品本身需求的原因,我们节日提醒时的带宽是平时的6倍左右,并发连接数是平时的25倍左右。
传统idc的带宽满足不了我们的扩容需求;在传统idc下,我们的系统架构,我们的费用预算也不能支撑这种级别的扩容需求,所以节日提醒的时候,我们带宽就会跑满,服务器负载也会暴增,服务可用率直线下降。
为了解决这些问题,在2016年前做了一些公有云的尝试后,在2016年,我们顺其自然地把所有服务迁移到了公有云上,建设了我们中华万年历的混合云数据中心。
混合云数据中心包括两部分:公有云和机柜托管区。
我们把原来自己的硬件服务器,放在了托管区。
公有云和托管区的网络是局域网可通信的,这样可以保证我们把计算节点放在公有云,把数据存储在自己托管区的服务器上。
自动扩容缩容平台
在Iaas支持带宽扩容、缩容,服务器按需计费的前提下,我们搭建了我们的自动化扩容缩容平台。
自动化扩容缩容平台两个核心组件:资源监控和自动扩容缩容。
资源监控主要是带宽和服务器负载,这些都可以通过监控中心api获得;
自动扩容缩容可以通过调用公有云的api来进行带宽和服务器的扩容缩容。
我们目前节日提醒的带宽一下子暴增到300M,并发连接数一下子暴增到140k,我们能保证和平时一样的可用率和响应时间。
节日提醒这个特殊场景的容量伸缩是我们已知的定时扩容缩容工作;在我们收到负载过高告警后,或者我们有一些临时扩容需求的时候,我们也提供了web化管理平台,可以很方便地扩容缩容。
同时,我们在客户端做了优化,把原来的10点集中访问,改成了10点前后10分钟左右分散访问。
同城双活
- 公有云同一可用区的不同数据中心,内网互通,比如我们的公有云有两个机房idc-b、idc-c;
- 我们的应用服务在上面的2个数据中心都会部署;
- 我们的数据存储(redis、mysql)如果把master部署idc-b,那么slave会部署在idc-c,保持数据同步;
- master-slave状态监控、master-slave自动切换(有确认机制)。
故障预警、处理不及时、事故频发的问题
故障不可怕,可怕的是你不能及时发现,及时恢复以及对故障不重视。针对这个问题,我们做了一下工作:
监控告警中心、事故管理平台、可用率保障小组。
监控告警中心
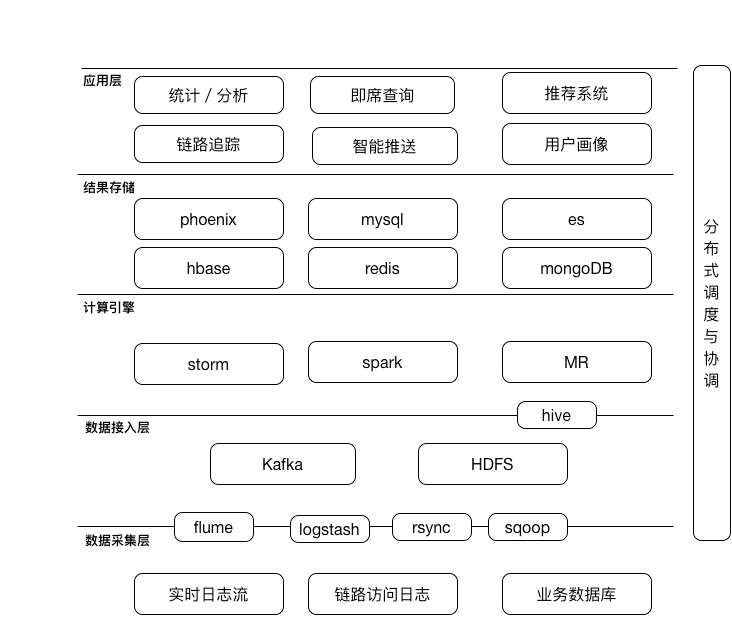
我们的监控中心包含了一下组件:
open-falcon:
这是我们监控告警的基础平台,所有服务器的基础指标监控,当然我们其他监控数据也会提交这里画图、告警。
应用进程监控:
我们有很多服务(nginx、tomcat、redis、mysql、大数据应用),我们有一个配置文件,上面记录所有主机上运行的应用、检测方法、异常处理方法;我们会把状态数据提交到open-falcon上展示和监控告警;同时会提交到数据库中存储,供我们的devops平台查询。
tomcat节点健康状态监控(我们的项目大部分是运行在tomcat上的java项目)
这里监控的不是进程也不是端口,这里是在内网直接通过curl tomcat node:port/url的方式来监控tomcat的上的java项目是否异常(因为有时候,tomcat 进程在,但是运行在上面的java项目异常了)
ELK
我们的ELK会收集nginx访问日志来统计分析和展示pv、uv等数据;
同时还会收集tomcat等错误日志,来告警和故障排查。
apm
这个主要是从公网不同的地方监测我们的url访问是否正常,来统计分析我们站点的可用率和响应时间。
链路追踪平台
基于设定的url,给每次访问打上一个traceId,我们把客户端提交上来的访问日志(http状态、响应时间、client的ip和运营商),nginx日志,tomcat日志提交到我们elastic,我们后端同事再统计分析展示在后台上;
我们在这个平台上,可以看到我们全国各地、不同运营商的client的真实访问情况;
也可以根据url,或者设备id来确定问题。
告警中心
open-falcon正常触发的告警我们会短信、邮件通知到处理人;白天一般看到就会处理了,不过晚上就不一定了,大家在睡大觉,有可能听不到告警短信,但是我们晚上没有专门的监控组,所以我们升级了告警机制;
告警升级机制:
加入电话语音告警;
在我们的open-falcon上会有所有未恢复的告警,
第一次告警我们会发到我们的ops组;
30min内没有处理,告警会发到CTO;
60min内没有处理,告警会发到CEO。
监控值班组:
建立晚上、节假日值班机制;
给我们运维同事配备了专门的值班电话,保证值班时段,电话畅通不静音。
事故管理平台
事故记录、总结;
事不过三。
可用率保障小组
我们的可用率kpi是ops和dev共同背的;
可用率kpi奖罚机制:
我们针对项目设定一个kpi对应的可用率;
同时设定一个奖励机制可用率;
超过kpi,触发了奖励机制可用率,我们有额外的奖励给到负责这个项目的可用率保障小组成员,跟kpi一样,按季度算。
应急小组
这里会包括各部门负责人,一起应对突发状况。
团队建设
- 我们SR和dev同属后台技术中心,共同负责项目的上线、发布、和可用性保障;
- 我们SR吸收有潜力、主动的应届生;
- 明确工作目标,突显工作价值;
- 保证日常工作和新技术的时间比。
devops的问题
上面简单介绍了下团队建设,主要是表达我们的dev和ops是一个部门;
但是我们还不是一个devops组织。
我们在落地devops的过程遇到了很多阻力:
一个最大的问题,就是dev不太懂ops,ops不太懂开发;
第二个问题,dev关注项目的上线变更速度,ops关注项目上线后的稳定性。
第二个问题,我们把dev、ops放到同一部门,共同背负kpi,共同实现价值。
第一个问题,我们整个技术后端,周期性的进行技术分享,共同学习,共同进步;
同时针对第一个问题我们在持续完善我们的devops平台,参考高效运维的devops全开源端到端部署流水线。
堡垒机
授权dev更简单、更安全的登入服务器进行一些非常规操作。
CMDB
开发自己的CMDB管理平台,并提供api给我们其他系统(ci、cd、job调度、批量配置中心等)
ci、cd持续构建、交付平台
我们用jekins搭建了ci持续构建平台,并连接了我们cd持续部署平台; dev可以不必等待ops来部署,dev可以自行发布到测试环境,发布到预发布环境、灰度发布、生产环境、回滚版本、重启指定服务、查看发布日志;
当然我们做了权限控制,保证必须发布到预发布通过后,才能发布到生产环境,同时发布到生产环境需要运维确认。
项目管理平台
- 项目配置中心:
基于项目的配置中心,可以看到该项目的接入LB ip、nginx节点、tomcat节点、redis节点、mysql节点,dev同事可以很清晰地看到该项目对应的各应用节点;
基于CMDB的nginx、tomcat等配置文件批量配置。 - 项目健康状态展示:
上文提到的应用进程监控会提交健康状态到数据库,这里会去获取这些状态数据并在前台染色,健康标绿,故障标红 - 对接到监控平台,可以访问到具体的监控数据。
任务调度平台
我们把一些常用的功能模块化,比如我们的发布脚本、重启脚本、应用进程监控脚本等等;
在上面我们可以集中管理我们crontab定时任务;
也可以给不同的组别,授权可以执行的jobs。
最终阶段 no ops
不忘初心,我们最终的目标是回归到 no ops,我们在devops的路上。
作者介绍
邹永红,微鲤运维经理。从0到1创立了随身云运维团队,负责中华万年历、微历、快马小报等的运维、系统保障等工作。